

In der heutigen Ära der Datenverarbeitung und Automatisierung gewinnt die Fähigkeit, Text aus Bildern zu extrahieren, zunehmend an Bedeutung. Hierbei spielt die optische Zeichenerkennung (OCR) eine zentrale Rolle. Pytesseract, eine Python-Bibliothek, die auf Googles Tesseract-OCR basiert, ermöglicht eine nahtlose Integration von Texterkennungsfunktionen in Python-Anwendungen. In diesem Artikel werfen wir einen genaueren Blick auf Pytesseract, seine Installation, Konfiguration und Verwendung, um präzise Texterkennung in Bildern zu ermöglichen.
Was ist Pytesseract?
Pytesseract ist eine leistungsstarke Python-Bibliothek, die auf Tesseract-OCR basiert und die Möglichkeit bietet, Text aus Bildern zu extrahieren. Tesseract-OCR ist eine Open-Source-Software, die von Google entwickelt wurde und auf optischer Zeichenerkennung (OCR) basiert. OCR ermöglicht es Computern, Text aus Bilddateien zu erkennen und in editierbaren Text umzuwandeln. Pytesseract erleichtert die Verwendung von Tesseract-OCR in Python-Anwendungen, indem es eine benutzerfreundliche Schnittstelle für die Texterkennung bietet.
Text aus Bild herauslesen mit Pytesseract – Schritt für Schritt
Die Verwendung von Pytesseract, um Text aus einem Bild auszulesen, ist relativ einfach. Hier sind die grundlegenden Schritte, die du befolgen kannst:
Tesseract unter Windows installieren
Ursprünglich für Linux entwickelt, steht Tesseract-OCR dank einer Initiative der Universität Mannheim nun auch für Windows zur Verfügung. Insbesondere wird Tesseract von der Universität Mannheim genutzt, um historische deutsche Zeitungen zu verarbeiten. Sie können den Windows-Installer für Tesseract auf GitHub herunterladen. Hier der Link: https://github.com/UB-Mannheim/tesseract/wiki
Dieser Installer ermöglicht Ihnen eine einfache und reibungslose Installation von Tesseract-OCR auf Ihrem Windows-System, um die Texterkennungsfunktionen mit Pytesseract nutzen zu können.
Hinweis: Falls das deutsche Sprachpaket noch nicht während der Tesseract-Installation eingeschlossen wurde, ist es notwendig, dieses separat zu installieren. Hierfür wird die Trainingsdaten für die deutsche Sprache benötigt, die heruntergeladen und anschließend in das Verzeichnis ‚tessdata‘ kopiert werden müssen. Dieses Verzeichnis befindet sich beispielsweise unter “C:\Program Files (x86)\Tesseract-OCR\tessdata”. Die Trainingsdaten für diverse Sprachen, einschließlich Deutsch, sind auf folgender Webseite zu finden: https://github.com/tesseract-ocr/tessdata/blob/main/deu.traineddata
Installation von Pytesseract
Nach der Installation von Tesseract auf Ihren Betriebssystem müssen wir noch über den Paketmanager pip die Module “Image” und “pytesseract” installieren.
pip install Image
pip install pytesseractModule importiere
Importieren Sie die erforderlichen Module in Ihrem Python-Code.
try:
from PIL import Image
except ImportError:
import Image
import pytesseractPfad zu Tesseract-OCR angeben
Geben Sie den Pfad zur Tesseract-OCR-Installation an, damit Pytesseract die ausführbare Datei finden kann.
# Passen Sie den Pfad entsprechend Ihrer Installation an
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
Bild eingeben
Laden Sie das Bild, aus dem Sie den Text extrahieren möchten, mit der Python Imaging Library (PIL).
image = Image.open('Ihr_Bild.png')Texterkennung durchführen
Nutzen Sie die image_to_string() Methode von Pytesseract, um den Text aus dem Bild zu extrahieren:
# Geben Sie den extrahierten Text aus:
extrahierter_text = pytesseract.image_to_string(image)
print(extrahierter_text)
Beispiel-Ausgabe
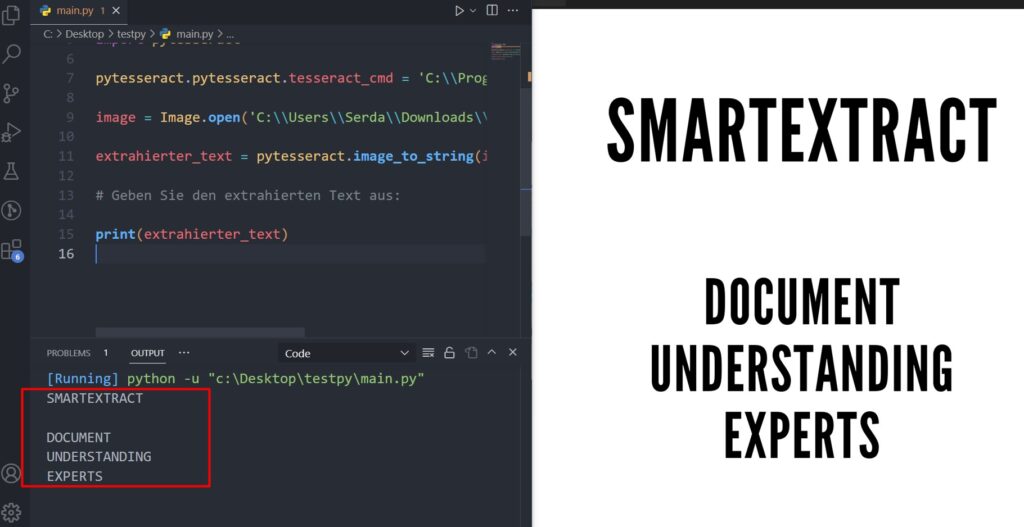
Fazit
Die Implementierung der optischen Zeichenerkennung (OCR) hat sich in der heutigen datengetriebenen Welt als essenziell erwiesen, und Pytesseract hat sich als unverzichtbares Werkzeug für diese Aufgabe etabliert. Die nahtlose Integration von Texterkennungsfunktionen in Python-Anwendungen macht es möglich, Text aus Bildern präzise zu extrahieren und in nutzbare Daten umzuwandeln.
Die Fähigkeit, Texte aus Bildern zu extrahieren, eröffnet viele Möglichkeiten zur Effizienzsteigerung und Optimierung von Arbeitsabläufen. Mit Pytesseract sind Entwickler in der Lage, den Wert von visuellen Daten in ihrer vollen Kapazität zu nutzen und innovative Lösungen zu schaffen, die auf präziser Texterkennung basieren.